Kamil Rarog
5
min read

There Is No Soft Launch for an AI Factory
The next bottleneck in AI infrastructure is not power or concrete. It is the software, the operating model, and the scarce human judgment needed to run dense AI facilities safely, and the industry is underwriting that risk far too lightly.
I spend most of my time talking to operators, and over the last year the conversation has changed in a way that should worry anyone building data centers. Two years ago the hard questions were about land, grid connections, and megawatts. Those are still hard. But increasingly the real question comes later in the meeting, and more quietly:
"We will have this thing energized in a few months. Are we actually ready to operate it?"
More often than the industry likes to admit, the honest answer is no.

The numbers tell one story
The sector is in the largest physical buildout in its history. McKinsey puts cumulative global data center CapEx near 6.7 trillion dollars by 2030, with AI workloads about 70 percent of capacity by decade's end. JLL expects nearly 100 GW of new capacity from 2026 to 2030, roughly doubling today's base. Goldman Sachs sees US data center power demand more than doubling, 31 GW in 2025 to 66 GW in 2027. And it is underway: at the end of Q3 2025, BloombergNEF tracked over 23 GW under construction worldwide, three quarters of it in the US.
The demand side is tighter still. CBRE recorded a North American primary-market vacancy rate of 1.4 percent at the end of 2025, the lowest on record, with under-construction capacity in the major markets still pre-leased in the mid-70 percent range.
Read that number twice, because it carries an operational consequence nobody says out loud: new facilities go live already full. No quiet ramp, no spare capacity to absorb the inevitable commissioning problems, no grace period while a new team finds its footing. The line goes hot on day one with a tenant already counting on it. There is no soft launch for an AI factory.
The shells are going up. The power is being arranged. The GPUs are being shipped. The physical layer is moving.
The question is whether the operational layer is on the same schedule.
The operational layer is not keeping up
Uptime Institute's 15th Global Data Center Survey of more than 800 operators found that operations management is now the single most acute skills gap, cited by 39 percent, the first time that category has topped the list. Nearly two thirds report trouble finding qualified candidates, keeping the staff they have, or both. Andy Lawrence, Uptime's Executive Director of Research, named it plainly: a "management shortage," with experienced leaders retiring just as the next wave of growth begins.
That is the gap in one sentence. Capital can be raised in a quarter. Concrete can be poured in months. A facility operations manager with twenty years of judgment cannot be conjured on the same schedule, and a generation of them is retiring at exactly the moment the industry needs them most.
The obvious objection is that labor markets correct themselves: pay rises, people retrain, supply responds. For most shortages that is right, here it holds only partway. Junior roles stay hard to fill, and there higher pay does help. But Uptime's data shows the shortage has expanded upward into senior and management roles, where the people leaving mostly go to competitors doing the same work, so higher wages move the same scarce judgment around rather than creating more of it. And no price compresses twenty years of judgment into the two to four years between groundbreaking and the line going hot. The buildout's own speed is what breaks the normal fix.
The half nobody is pricing
The gap is sharpest where the money is going, and dense GPU infrastructure is getting more unforgiving as clusters grow. The most-cited evidence is still Meta's Llama 3 trace: one unexpected interruption roughly every three hours across 16,384 GPUs over 54 days, cited so often because almost no operator has published a failure trace in that detail. By 2026 it reads as a floor, not a worst case. All else equal, failure exposure rises with GPU count, even if good architecture and recovery soften the impact, and frontier clusters now run past 100,000 GPUs. Independent estimates put a cluster that size near one hardware failure every 30 minutes, production reports agree, Microsoft describing failures on the order of tens of minutes and ByteDance at least one a day. Put that profile inside a production facility, run by a thinner and less experienced bench than ever, against an SLA that assumes the line never stops.
And the missing number matters, because the industry quantifies only one half of this. Every figure on the buildout side is precise. The capex is costed to the significant figure: 6.7 trillion dollars. The power is contracted to the megawatt. The schedule is tracked to the quarter. The operational risk that decides whether any of that capital performs is, in most underwriting, costed at roughly nothing.
It is not hard to price. As an illustrative floor, at 2.50 dollars per GPU-hour a 100,000-GPU cluster is about 250,000 dollars of compute an hour, and the meter does not pause when it stalls. Uptime finds 57 percent of major outages now cost over 100,000 dollars, one in five over a million. And because the halls are pre-leased, downtime has a counterparty from the first hour: credits and penalties accrue immediately, and in large agreements the exposure compounds fast. We model the cost of building these places to four significant figures. We still treat the cost of failing to run them as an afterthought.
Why more monitoring will not close the gap
The instinctive response to an operational gap is to buy more monitoring. More sensors, more dashboards, more alerts. It is necessary, and it is nowhere near sufficient.
A modern AI hall produces telemetry from at least five disconnected worlds: building management, electrical metering at PDUs and busways, environmental monitoring, liquid-cooling instrumentation, and the IT layer through interfaces like Redfish and GPU telemetry. Each came from a different vendor, with a different data model, for a different audience. The coupling is tightening, too: as the densest racks move to liquid cooling, a loss of flow or a CDU fault can push a packed hall toward shutdown faster than a ticket can be opened. When a hot spot appears at two in the morning, correlating it to the throttling GPU, the rack drawing too much current, and the cooling loop below spec is a forensic exercise. The investigation takes hours. The event that caused it takes seconds.

That is the heart of it. The failure modes of an AI factory move on a time scale that ticket-based, human-in-the-loop operations cannot match, and they are coupled across domains that legacy DCIM treats as separate. A throttle event is a thermal event is a power event is a workload event, all at once. Tooling built to track inventory and report PUE for an air-cooled Colo was never meant to reason about that.
What operational readiness actually requires
So what does operational readiness actually require? In my view it comes down to two capabilities that have to work together: a trustworthy operational model of the facility, and a governed action layer that can act on it safely.
The first is a single, faithful model of the facility: not five dashboards side by side, but one operational twin holding the physical layout, every rack and server, the live thermal and power state, and the real topology across network, power, and cooling. Each cabinet is a real object, not a generic box, an air-cooled DGX rack and a liquid-cooled GB200 cabinet in the same model as what they are, beside the spines that feed them.
The operator moves from facility state down to a server and the dependencies between them without changing tools. The point is not visual polish. It is that power, thermal, cooling, topology, and IT state collapse into one causal picture, so a fault in one domain can be traced to its cause in another.
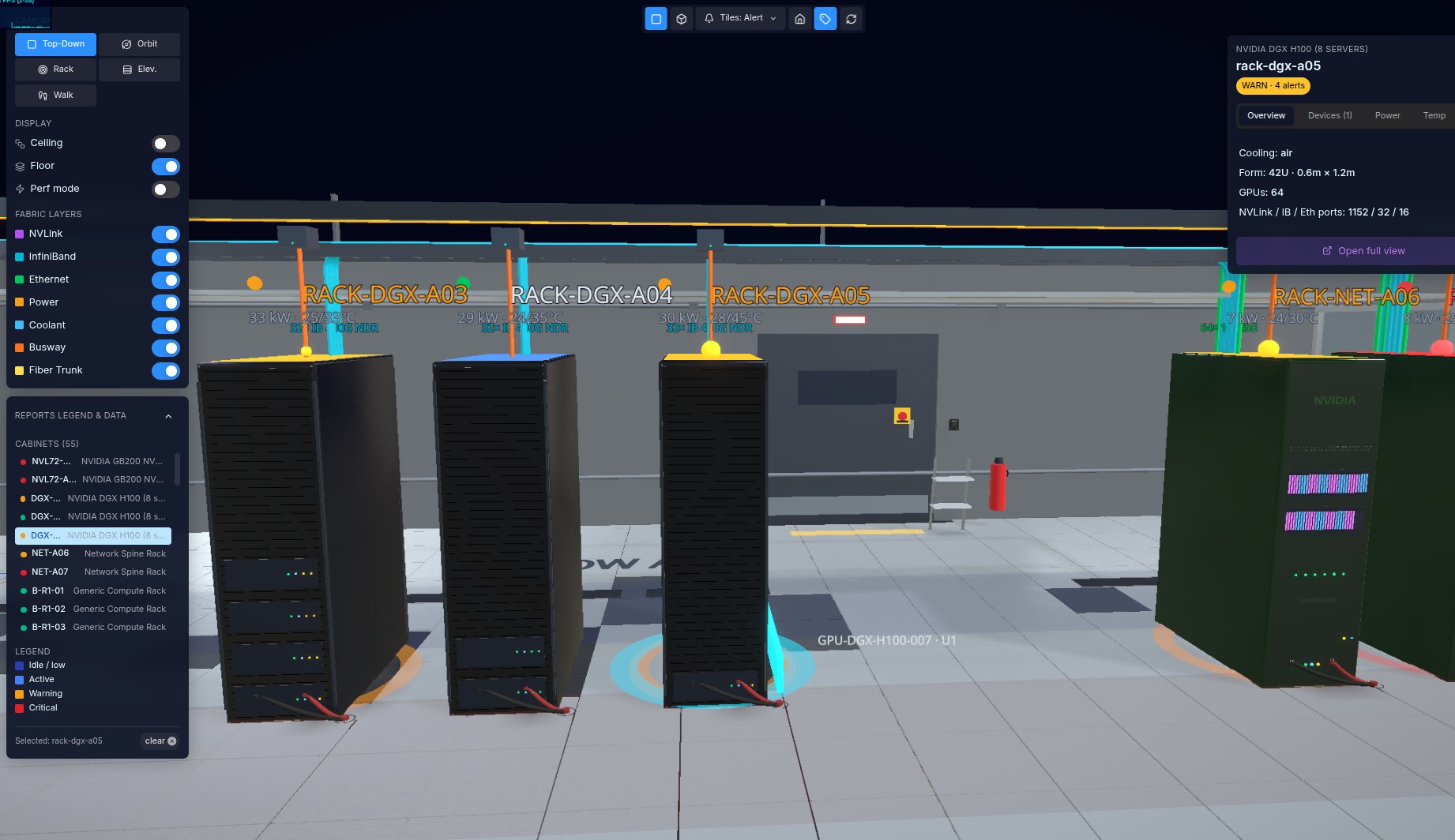
Here is what that buys you when it matters. A rack flips to a warning at 45 degrees exhaust while its neighbors sit near 33. Conventionally that starts an investigation, on the twin it can end one: the warm rack is drawing less power than its cooler neighbor, so the problem is not load, it is airflow or a cooling loop at that position. Four signals in four systems become one picture, read rather than reconstructed.
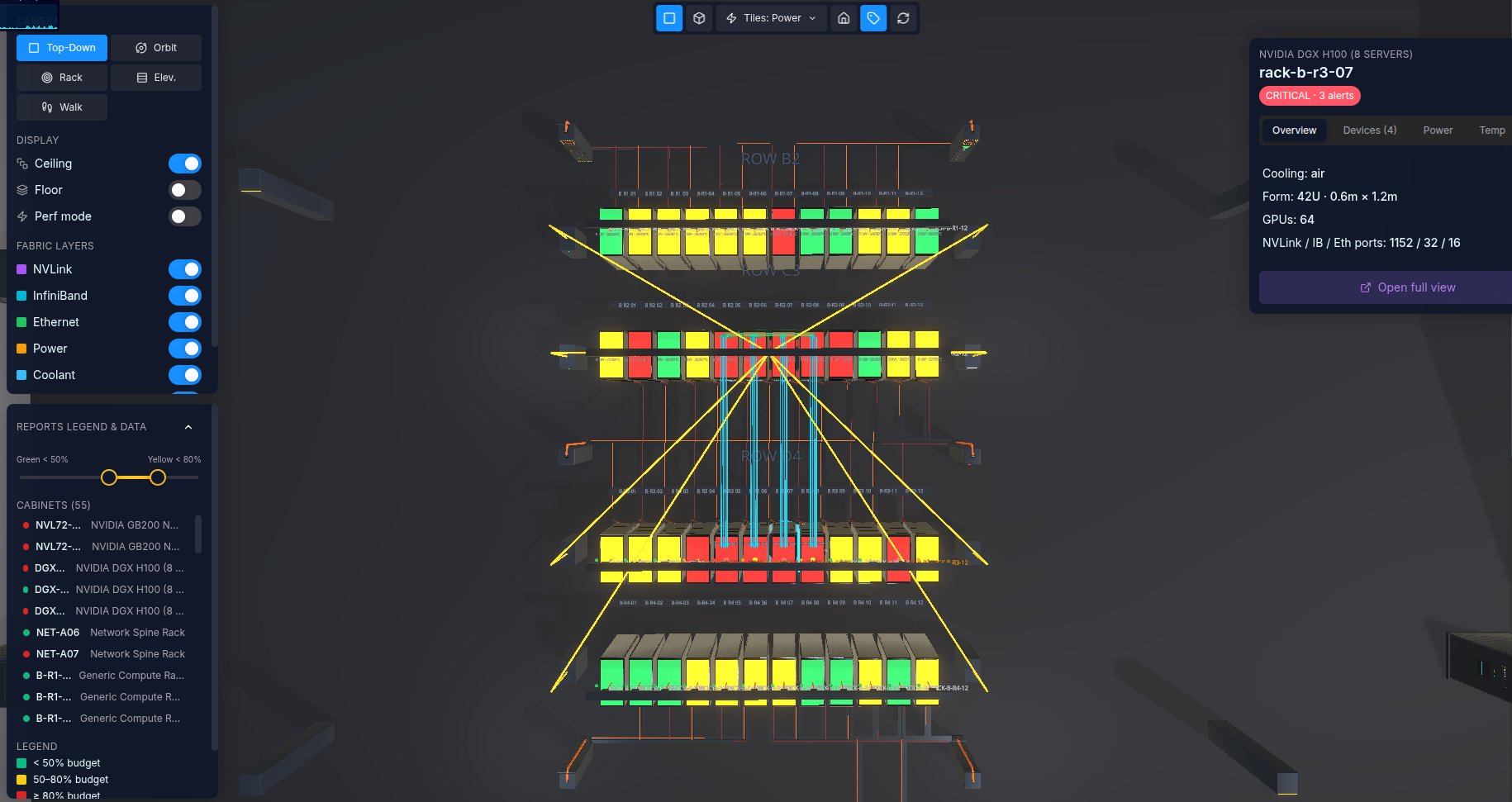
The second capability is letting software act. A model that only watches still leaves a human in the critical path, and the human bench is the constraint. This is where the industry is most cautious, rightly. The question is not whether operators should hand the facility to an AI, they should not. It is which narrow classes of action can be made visible, bounded, reversible, and safe enough to automate once proven many times over.
The data backs the caution. Uptime found operators will let AI analyze sensor data and run predictive maintenance, but draw a hard line at changing configurations or controlling equipment. Gartner expects more than 40 percent of agentic AI projects to be cancelled by the end of 2027, undone by runaway cost, unclear value, and inadequate risk controls. Overreaching on autonomy is not a hypothetical failure mode. It is the most likely one.
So the action layer earns its way across that line rather than leaping it. It runs as a structured loop, not a black box: detect, diagnose with several independent models each reporting a confidence, choose a strategy, execute a bounded, reversible action inside explicit policy, then validate and learn. It begins recommend-only and widens its envelope one class of problem at a time, only where it has proven itself. Every step is visible, scored, timed, and reversible.
And there is a class where recommend-only is the permanent ceiling, not a starting point. The model rests on actions being bounded and reversible, some are not. Direct manipulation of primary cooling or electrical distribution on a populated hall can drive a thermal or electrical excursion faster than any loop can validate it, and it does not roll back: you cannot un-overheat a rack of GPUs, and the reversal of a bad switching action is a cold start, not an undo. For that class the engine stays advisory and a human authorizes the move, however much trust it has earned elsewhere. Treating that boundary as an inconvenience to automate away is exactly the mistake that becomes one of Gartner's cancelled projects. Some lines are meant to stay drawn.
This is not theoretical, and it is not a roadmap slide. It is the same engine we already run against live incidents today.
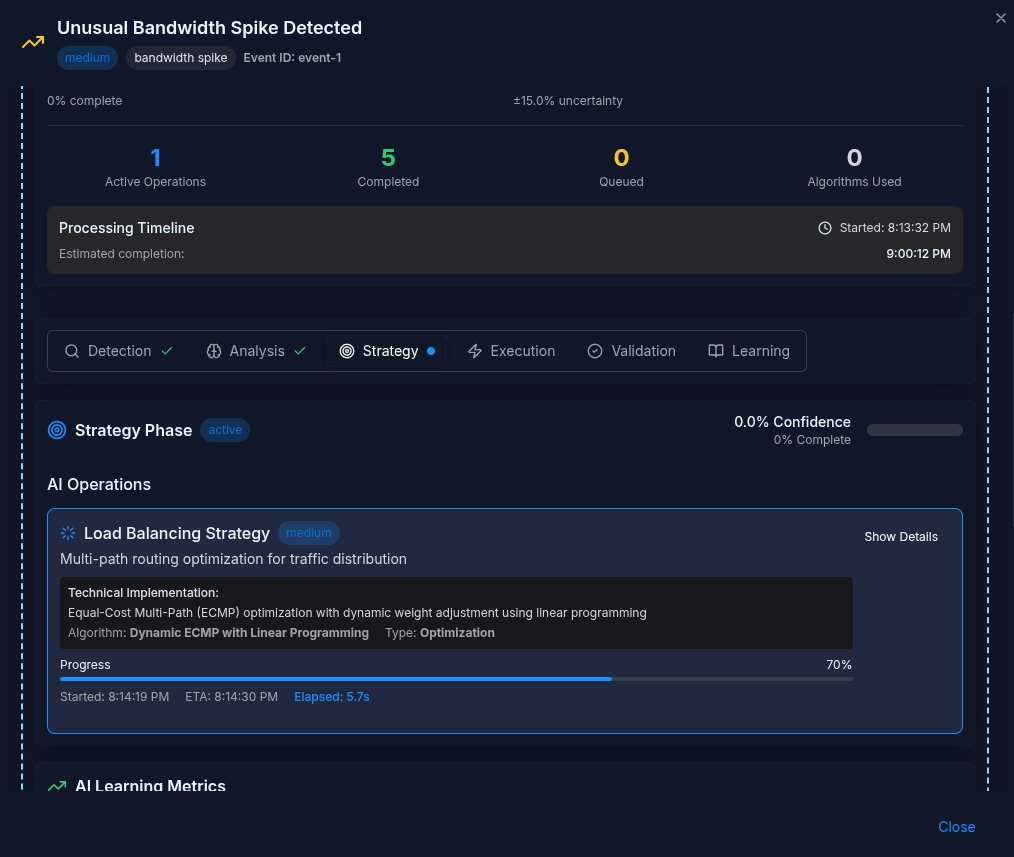
When a bandwidth anomaly trips, a statistical detector flags the deviation, then independent models classify it, deep packet inspection at about 94 percent confidence, a behavioral model close behind, each with its method and confidence stated rather than asserted.

Only then does the engine act, reconfiguring routing and load balancing through device APIs, with failover time, latency, and accuracy measured as the change lands. The operator watches the reasoning, not just the outcome.

That loop runs on telecom networks today, because operators there ran out of people to run them by hand years ago. Pointing it at the data center hall is the bridge we are building now, the actions just change domain: reroute traffic becomes rebalance a cooling loop, reweight servers becomes drain a node or throttle a workload. The engine reasons over the operational twin instead of the network graph, but it is the same closed loop, the operator supervising rather than first-responding.
That also resolves the apparent contradiction in the staffing argument. The goal is not to remove the experienced operator, which only reproduces the shortage, but to multiply one, and the arithmetic is not vague. The installed base is set to roughly double by 2030 while the senior bench is flat at best. Each experienced operator's span of control therefore has to roughly double just to stand still, before the new capacity's greater density. That does not close by hiring. It closes by giving one senior operator a system that handles first response across many rooms while their judgment governs all of them, the shift Gartner frames as moving from doer to supervisor. The judgment stays human, the first response does not have to be. Bluntly, the industry has to run dense capacity with fewer experienced humans per megawatt, because that is the only configuration the next five years allow.
This is no longer fringe. Gartner's Predicts 2026 research projects 70 percent of enterprises deploying agentic AI in IT infrastructure operations by 2029, up from under 5 percent in 2025. But the number is not the point. The condition underneath it is: agentic operations only work when the agent has a trustworthy model to reason over and a disciplined, governed action layer on top. The direction of travel is settled. That combination is what remains scarce.
Where this leaves us
The buildout will continue. The capital is committed, the demand is real, and much of the construction will get done. But construction was never the only constraint.
The constraint is everything after the ribbon is cut. The industry has poured extraordinary energy into making these facilities buildable and powerable, and far less into making them operable, at density, by a workforce shrinking in experience as the workload grows in complexity. That is the gap I keep running into, one quiet question at a time.
At TelcoBrain we built digital twins for networks that had to run themselves, and the autonomous loop on top, because telecom operators ran out of people to run them by hand years ago. Extending it to the data center hall, the same closed loop pointed at power, cooling, and workload, is the same problem in a new building. The data center world is arriving where telecom already is, faster than most expected.
The next winners in AI infrastructure will not be those who build the most capacity, but those who can operate dense capacity safely, predictably, and with fewer experienced humans per megawatt. The facilities are being built with extraordinary seriousness. The operational layer has to be built with the same seriousness, and for the halls going hot on day one, with no soft launch to hide behind, it has to be ready on the same morning the line is.


